
Otimizar a alocação de recursos de computação para atingir as metas de desempenho e, ao mesmo tempo, controlar os custos pode ser um equilíbrio difícil de alcançar, especialmente para cargas de trabalho de banco de dados com padrões de uso complexos. Para ajudar a resolver esses desafios, temos o prazer de anunciar a visualização do banco de dados SQL do Azure sem servidor. O SQL Database serverless (preview) é uma nova camada de computação que otimiza a relação preço-desempenho e simplifica o gerenciamento de desempenho para bancos de dados com uso intermitente e imprevisível. Aplicativos de linha de negócios, bancos de dados de desenvolvimento / teste, gerenciamento de conteúdo e sistemas de e-commerce são apenas alguns exemplos – em uma variedade de aplicativos – que geralmente se encaixam no padrão de uso ideal para o SQL Database serverless.
O SQL Serverless do servidor de banco de dados também é adequado para novos aplicativos com incerteza de dimensionamento de computador ou cargas de trabalho que exigem reescalonamento frequente para reduzir os custos. A camada de computação sem servidor desfruta de todos os benefícios de inteligência incorporados e totalmente gerenciados do Banco de Dados SQL e ajuda a acelerar o desenvolvimento de aplicativos, minimizar a complexidade operacional e reduzir os custos totais.
Computação com o escalonamento automático
O SQL Server serverless dimensiona automaticamente a computação para bancos de dados individuais com base na demanda de carga de trabalho e nas contas de computação usadas por segundo. Em contraste com a camada de computação provisionada no Banco de Dados SQL, que aloca uma quantidade fixa de recursos de computação por um preço fixo e é faturada por hora.
Em escalas de tempo curtas, os bancos de dados de computação provisionados devem provisionar recursos em excesso a um custo, a fim de acomodar o pico de uso ou subprovisionar e arriscar oferecer desempenho ruim. Em escalas de tempo maiores, os bancos de dados de computação provisionados podem ser redimensionados, mas essa solução pode exigir a previsão de padrões de uso ou a gravação de lógica personalizada para acionar operações de redimensionamento com base em uma programação ou métricas de desempenho. Isso aumenta o desenvolvimento e a complexidade operacional.
No serverless, O dimensionamento de computação dentro de limites configuráveis é gerenciado pelo serviço para dimensionar recursos de forma contínua. O Serverless também oferece uma opção para pausar automaticamente o banco de dados durante períodos de uso inativos e retomar automaticamente quando a atividade retorna.
Pague apenas pelo que for usado
No SQL Server serverless, o cálculo é faturado apenas com base na quantidade de CPU e memória usada por segundo. Enquanto o banco de dados é pausado, apenas o armazenamento é cobrado, proporcionando um benefício adicional de otimização de preço.
Considere um aplicativo de linha de negócios ou um banco de dados de desenvolvimento / teste que esteja ocioso à noite, mas que precise de margem de expansão de vários núcleos ao longo do dia. Neste exemplo, o aplicativo está usando serverless configurado para permitir a pausa automática e o escalonamento automático de até 4 vcores e possui o seguinte padrão de uso em um período de 24 horas:
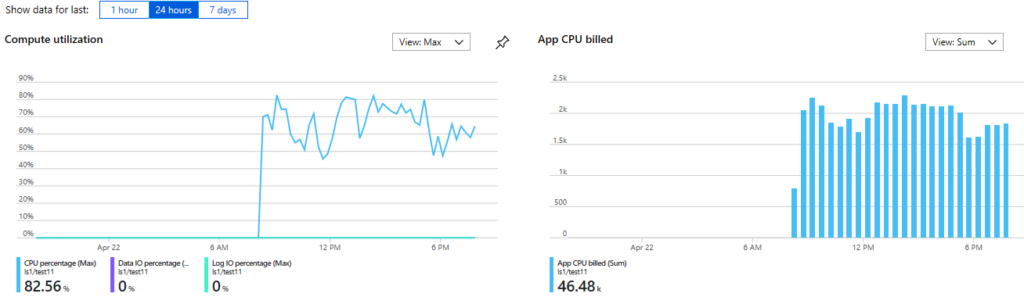
Como pode ser visto, o uso do banco de dados corresponde à quantidade de computação faturada, que é medida em unidades de segundos vcore e aumenta para cerca de 46k segundos vcore ao longo do período de 24 horas. Suponha que o preço unitário de computação do banco de dados serverless esteja em torno de US $ 0,000073 / vcore / segundo. Então, a conta de computação para este período de um dia é de apenas US$ 3,40.
Isso é calculado multiplicando o preço unitário de computação pelo número total de segundos do vcore acumulado. Durante esse período de tempo, o banco de dados foi pausado automaticamente enquanto ocioso e desfrutou do benefício de interromper episódios em até 80% de 4 vcores sem intervenção do cliente. Neste exemplo, a economia de preço usando o serverless é significativa em comparação com um banco de dados de computação provisionado configurado com o mesmo limite de quatro vcore.
Preço-desempenho trade-offs
Ao usar o SQL Database serverless, há trade-offs de preço-desempenho a serem considerados. Essas compensações estão relacionadas ao preço unitário de computação e ao impacto no desempenho do aplicativo devido ao cálculo do aquecimento após períodos de baixo uso ou inatividade.
Preço unitário computado
O preço unitário de computação é maior para um banco de dados sem servidor do que para um banco de dados de computação provisionado, pois o serverless é otimizado para cargas de trabalho com padrões de uso intermitentes. Se o uso da CPU ou da memória for alto o suficiente e mantido por tempo suficiente, a camada de computação provisionada poderá ser mais barata.
Calcular o aquecimento após um baixo uso
Enquanto um banco de dados sem servidor está on-line, a memória é gradualmente recuperada se o uso da CPU ou da memória for baixo o suficiente por tempo proporcional. Quando a atividade da carga de trabalho retorna, o I/O do disco pode ser necessário para reidratar as páginas de dados no pool de buffer SQL ou os planos de consulta podem precisar ser recompilados. Essa política de gerenciamento de memória para recuperar o cache com base no baixo uso é exclusiva para serverless e feita para controlar os custos do cliente, mas pode afetar o desempenho. A recuperação de memória com base no baixo uso não ocorre na camada de computação provisionada para bancos de dados individuais ou conjuntos elásticos, onde esse tipo de impacto pode ser evitado.
Calcular o aquecimento após a pausa
A latência para pausar e retomar um banco de dados sem servidor é geralmente em torno de um minuto ou menos, período em que o banco de dados está offline. Depois que o banco de dados é retomado, os caches de memória precisam ser reidratados, o que adiciona latência adicional antes que as condições ideais de desempenho retornem. O período ocioso que deve decorrer antes de ocorrer a pausa automática pode ser configurado para compensar esse impacto no desempenho. Como alternativa, a pausa automática pode ser desativada para cargas de trabalho sensíveis a esse impacto e ainda se beneficiar do escalonamento automático. Os mínimos computacionais são faturados enquanto o banco de dados está on-line, independentemente do uso. Portanto, desabilitar a pausa automática pode aumentar os custos.
Artigo publicado originalmente em inglês, no blog oficial da Microsoft.